
Many of today’s most innovative computation-based products and solutions are fueled by data. Where those data are private, it is essential to protect them and to prevent the release of information about data subjects, owners, or users to the wrong parties. How can we perform useful computations on sensitive data while preserving privacy?

We will revisit two well-studied approaches to this challenge: secure multiparty computation (MPC) and differential privacy (DP). MPC and DP were invented to address different real-world problems and to achieve different technical goals. However, because they are both aimed at using private information without fully revealing it, they are often confused. To help draw a distinction between the two approaches, we will discuss the power and limitations of both and give typical scenarios in which each can be highly effective.
We are interested in scenarios in which multiple individuals (sometimes, society as a whole) can derive substantial utility from a computation on private data but, in order to preserve privacy, cannot simply share all of their data with each other or with an external party.
Secure multiparty computation
MPC methods allow a group of parties to collectively perform a computation that involves all of their private data while revealing only the result of the computation. More formally, an MPC protocol enables n parties, each of whom possesses a private dataset, to compute a function of the union of their datasets in such a way that the only information revealed by the computation is the output of the function. Common situations in which MPC can be used to protect private interests include
- auctions: the winning bid amount should be made public, but no information about the losing bids should be revealed;
- voting: the number of votes cast for each option should be made public but not the vote cast by any one individual;
- machine learning inference: secure two-party computation enables a client to submit a query to a server that holds a proprietary model and receive a response, keeping the query private from the server and the model private from the client.

Note that the number n of participants can be quite small (e.g., two in the case of machine learning inference), moderate in size, or very large; the latter two size ranges both occur naturally in auctions and votes. Similarly, the participants may be known to each other (as they would be, for example, in a departmental faculty vote) or not (as, for example, in an online auction). MPC protocols mathematically guarantee the secrecy of input values but do not attempt to hide the identities of the participants; if anonymous participation is desired, it can be achieved by combining MPC with an anonymous-communication protocol.
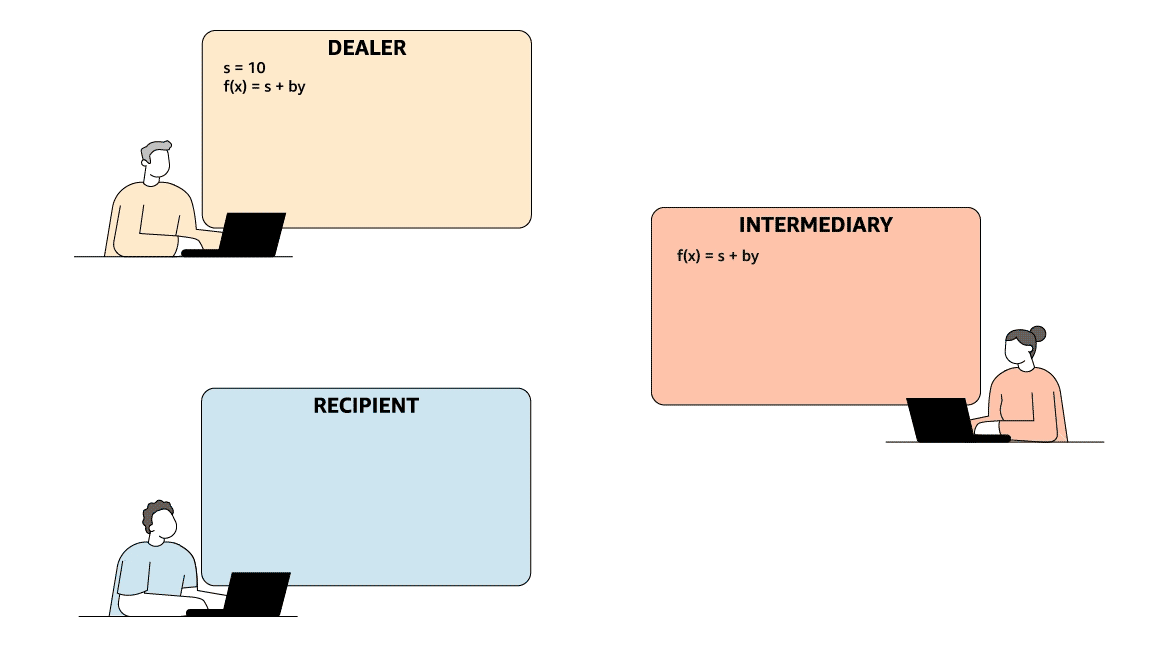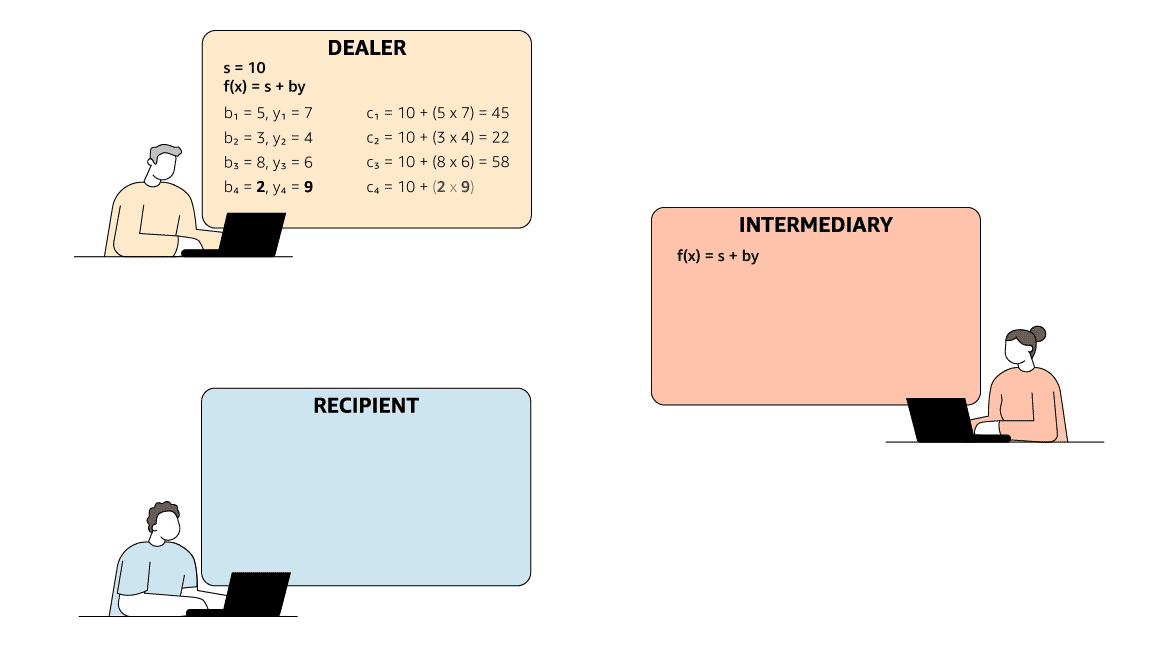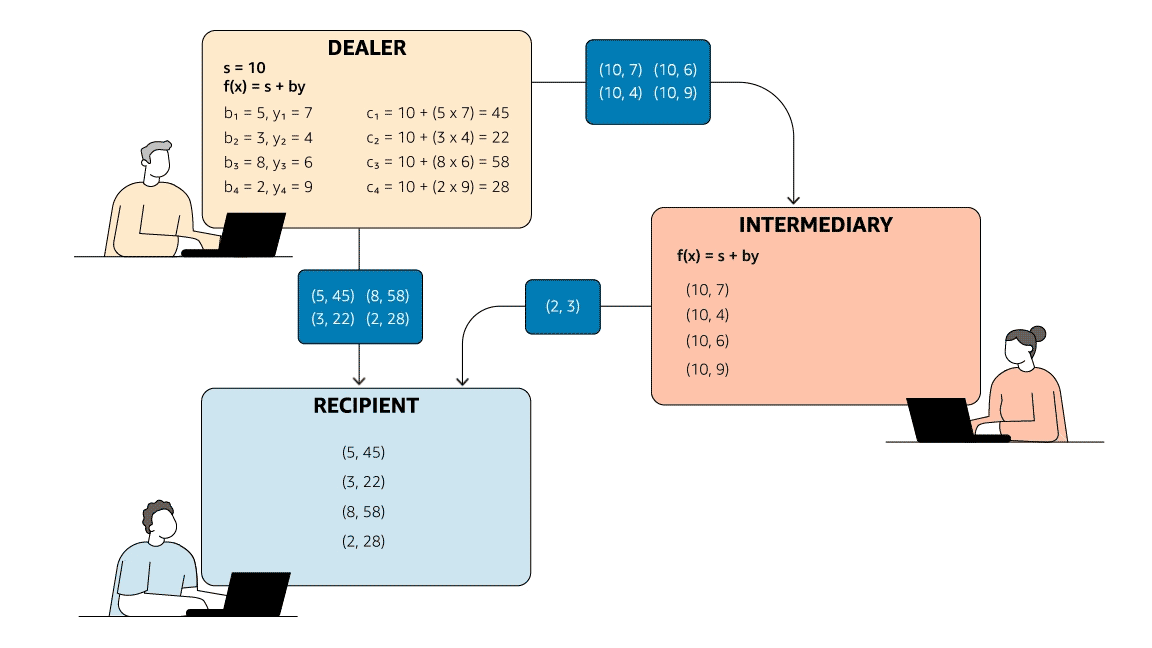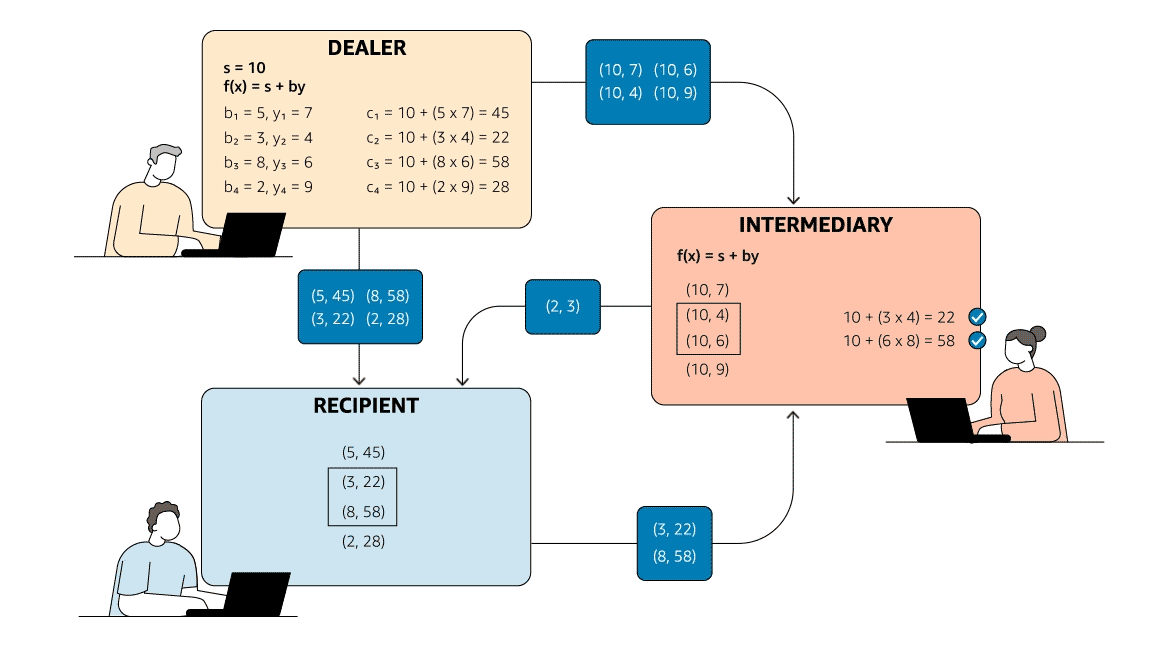
Although MPC may seem like magic, it is implementable and even practical using cryptographic and distributed-computing techniques. For example, suppose that Alice, Bob, Carlos, and David are four engineers who want to compare their annual raises. Alice selects four random numbers that sum to her raise. She keeps one number to herself and gives each of the other three to one of the other engineers. Bob, Carlos, and David do the same with their own raises.
After everyone has distributed the random numbers, each engineer adds up the numbers he or she is holding and sends the sum to the others. Each engineer adds up these four sums privately (i.e., on his or her local machine) and divides by four to get the average raise. Now they can all compare their raises to the team average.
| | Amount | Alice's share | Bob's share | Carlos's share | David's share | Sum of sums |
| Alice's raise | 3800 | -1000 | 2500 | 900 | 1400 | |
| Bob's raise | 2514 | 700 | 400 | 650 | 764 | |
| Carlos's raise | 2982 | 750 | -100 | 832 | 1500 | |
| David's raise | 3390 | 1500 | 900 | -3000 | 3990 | |
| Sum | 12686 | 1950 | 3700 | -618 | 7654 | 12686 |
| Average | 3171.5 | | | | | 3171.5 |
Note that, because Alice (like Bob, Carlos, and David) kept part of her raise private (the bold numbers), no one else learned her actual raise. When she summed the numbers she was holding, the sum didn’t correspond to anyone’s raise. In fact, Bob’s sum was negative, because all that matters is that the four chosen numbers add up to the raise; the sign and magnitude of these four numbers are irrelevant.
Summing all of the engineers’ sums results in the same value as summing the raises directly, namely $12,686. If all of the engineers follow this protocol faithfully, dividing this value by four yields the team average raise of $3,171.50, which allows each person to compare his or her raise against the team average (locally and hence privately) without revealing any salary information.
A highly readable introduction to MPC that emphasizes practical protocols, some of which have been deployed in real-world scenarios, can be found in a monograph by Evans, Kolesnikov, and Rosulek. Examples of real-world applications that have been deployed include analysis of gender-based wage gaps in Boston-area companies, aggregate adoption of cybersecurity measures, and Covid exposure notification. Readers may also wish to read our previous blog post on this and related topics.
Differential privacy
Differential privacy (DP) is a body of statistical and algorithmic techniques for releasing an aggregate function of a dataset without revealing the mapping between data contributors and data items. As in MPC, we have n parties, each of whom possesses a data item. Either the parties themselves or, more often, an external agent wishes to compute an aggregate function of the parties’ input data.

If this computation is performed in a differentially private manner, then no information that could be inferred from the output about the ith input, xi, can be associated with the individual party Pi. Typically, the number n of participants is very large, the participants are not known to each other, and the goal is to compute a statistical property of the set {x1, …, xn} while protecting the privacy of individual data contributors {P1, …, Pn}.
In slightly more detail, we say that a randomized algorithm M preserves differential privacy with respect to an aggregation function f if it satisfies two properties. First, for every set of input values, the output of M closely approximates the value of f. Second, for every distinct pair (xi, xi') of possible values for the ith individual input, the distribution of M(x1, …, xi,…, xn) is approximately equivalent to the distribution of M(x1, …, xi′, …, xn). The maximum “distance” between the two distributions is characterized by a parameter, ϵ, called the privacy parameter, and M is called an ϵ-differentially private algorithm.
Note that the output of a differentially private algorithm is a random variable drawn from a distribution on the range of the function f. That is because DP computation requires randomization; in particular, it works by “adding noise.” All known DP techniques introduce a salient trade-off between the privacy parameter and the utility of the output of the computation. Smaller values of ϵ produce better privacy guarantees, but they require more noise and hence produce less-accurate outputs; larger values of ϵ yield worse privacy bounds, but they require less noise and hence deliver better accuracy.
For example, consider a poll, the goal of which is to predict who is going to win an election. The pollster and respondents are willing to sacrifice some accuracy in order to improve privacy. Suppose respondents P1, …, Pn have predictions x1, …, xn, respectively, where each xi is either 0 or 1. The poll is supposed to output a good estimate of p, which we use to denote the fraction of the parties who predict 1. The DP framework allows us to compute an accurate estimate and simultaneously to preserve each respondent’s “plausible deniability” about his or her true prediction by requiring each respondent to add noise before sending a response to the pollster.

We now provide a few more details of the polling example. Consider the algorithm m that takes as input a bit xi and flips a fair coin. If the coin comes up tails, then m outputs xi; otherwise m flips another fair coin and outputs 1 if heads and 0 if tails. This m is known as the randomized response mechanism; when the pollster asks Pi for a prediction, Pi responds with m(xi). Simple statistical calculation shows that, in the set of answers that the pollster receives from the respondents, the expected fraction that are 1’s is
Pr[First coin is tails] ⋅ p + Pr[First coin is heads] ⋅ Pr[Second coin is heads] = p/2 + 1/4.
Thus, the expected number of 1’s received is n(p/2 + 1/4). Let N = m(x1) + ⋅⋅⋅ + m(xn) denote the actual number of 1’s received; we approximate p by M(x1, …, xn) = 2N/n − 1/2. In fact, this approximation algorithm, M, is differentially private. Accuracy follows from the statistical calculation, and privacy follows from the “plausible deniability” provided by the fact that M outputs 1 with probability at least 1/4 regardless of the value of xi.
Differential privacy has dominated the study of privacy-preserving statistical computation since it was introduced in 2006 and is widely regarded as a fundamental breakthrough in both theory and practice. An excellent overview of algorithmic techniques in DP can be found in a monograph by Dwork and Roth. DP has been applied in many real-world applications, most notably the 2020 US Census.
The power and limitations of MPC and DP
We now review some of the strengths and weaknesses of these two approaches and highlight some key differences between them.
Secure multiparty computation
MPC has been extensively studied for more than 40 years, and there are powerful, general results showing that it can be done for all functions f using a variety of cryptographic and coding-theoretic techniques, system models, and adversary models.
Despite the existence of fully general, secure protocols, MPC has seen limited real-world deployment. One obstacle is protocol complexity — particularly the communication complexity of the most powerful, general solutions. Much current work on MPC addresses this issue.

More-fundamental questions that must be answered before MPC can be applied in a given scenario include the nature of the function f being computed and the information environment in which the computation is taking place. In order to explain this point, we first note that the set of participants in the MPC computation is not necessarily the same as the set of parties that receive the result of the computation. The two sets may be identical, one may be a proper subset of the other, they may have some (but not all) elements in common, or they may be entirely disjoint.
Although a secure MPC protocol (provably!) reveals nothing to the recipients about the private inputs except what can be inferred from the result, even that may be too much. For example, if the result is the number of votes for and votes against a proposition in a referendum, and the referendum passes unanimously, then the recipients learn exactly how each participant voted. The referendum authority can avoid revealing private information by using a different f, e.g., one that is “YES” if the number of votes for the proposition is at least half the number of participants and “NO” if it is less than half.
This simple example demonstrates a pervasive trade-off in privacy-preserving computation: participants can compute a function that is more informative if they are willing to reveal private information to the recipients in edge cases; they can achieve more privacy in edge cases if they are willing to compute a less informative function.
In addition to specifying the function f carefully, users of MPC must evaluate the information environment in which MPC is to be deployed and, in particular, must avoid the catastrophic loss of privacy that can occur when the recipients combine the result of the computation with auxiliary information. For example, consider the scenario in which the participants are all of the companies in a given commercial sector and metropolitan area, and they wish to use MPC to compute the total dollar loss that they (collectively) experienced in a given year that was attributable to data breaches; in this example, the recipients of the result are the companies themselves.

Suppose further that, during that year, one of the companies suffered a severe breach that was covered in the local media, which identified the company by name and reported an approximate dollar figure for the loss that the company suffered as a result of the breach. If that approximate figure is very close to the total loss imposed by data breaches on all the companies that year, then the participants can conclude that all but one of them were barely affected by data breaches that year.
Note that this potentially sensitive information is not leaked by the MPC protocol, which reveals nothing but the aggregate amount lost (i.e., the value of the function f). Rather, it is inferred by combining the result of the computation with information that was already available to the participants before the computation was done. The same risk that input privacy will be destroyed when results are combined with auxiliary information is posed by any computational method that reveals the exact value of the function f.
Differential privacy
The DP framework provides some elegant, simple mechanisms that can be applied to any function f whose output is a vector of real numbers. Essentially, one can independently perturb or “noise up” each component of f(x) by an appropriately defined random value. The amount of noise that must be added in order to hide the contribution (or, indeed, the participation) of any single data subject is determined by the privacy parameter and the maximum amount by which a single input can change the output of f. We explain one such mechanism in slightly more mathematical detail in the following paragraph.
One can apply the Laplace mechanism with privacy parameter ϵ to a function f, whose outputs are k-tuples of real numbers, by returning the value f(x1, …, xn) + (Y1, …, Yk) on input (x1, …, xn), where the Yi are independent random variables drawn from the Laplace distribution with parameter Δ(f)/ϵ. Here Δ(f) denotes the ℓ1sensitivity of the function f, which captures the magnitude by which a single individual’s data can change the output of f in the worst case. The technical definition of the Laplace distribution is beyond the scope of this article, but for our purposes, its important property is that the Yi can be sampled efficiently.

Crucially, DP protects data contributors against privacy loss caused by post-processing computational results or by combining results with auxiliary information. The scenario in which privacy loss occurred when the output of an MPC protocol was combined with information from an existing news story could not occur in a DP application; moreover, no harm could be done by combining the result of a DP computation with auxiliary information in a future news story.
DP techniques also benefit from powerful composition theorems that allow separate differentially private algorithms to be combined in one application. In particular, the independent use of an ϵ1-differentially private algorithm and an ϵ2-differentially private algorithm, when taken together, is (ϵ1 + ϵ2)-differentially private.
One limitation on the applicability of DP is the need to add noise — something that may not be tolerable in some application scenarios. More fundamentally, the ℓ1 sensitivity of a function f, which yields an upper bound on the amount of noise that must be added to the output in order to achieve a given privacy parameter ϵ, also yields a lower bound. If the output of f is strongly influenced by the presence of a single outlier in the input, then it is impossible to achieve strong privacy and high accuracy simultaneously.
For example, consider the simple case in which f is the sum of all of the private inputs, and each input is an arbitrary positive integer. It is easy to see that the ℓ1 sensitivity is unbounded in this case; to hide the contribution or the participation of an individual whose data item strongly dominates those of all other individuals would require enough noise to render the output meaningless. If one can restrict all of the private inputs to a small interval [a,b], however, then the Laplace mechanism can provide meaningful privacy and accuracy.
DP was originally designed to compute statistical aggregates while preserving the privacy of individual data subjects; in particular, it was designed with real-valued functions in mind. Since then, researchers have developed DP techniques for non-numerical computations. For example, the exponential mechanism can be used to solve selection problems, in which both input and output are of arbitrary type.

In specifying a selection problem, one must define a scoring function that maps input-output pairs to real numbers. For each input x, a solution y is better than a solution y′ if the score of (x,y) is greater than that of (x,y′). The exponential mechanism generally works well (i.e., achieves good privacy and good accuracy simultaneously) for selection problems (e.g., approval voting) that can be defined by scoring functions of low sensitivity but not for those (e.g., set intersection) in which the scoring function must have high sensitivity. In fact, there is no differentially private algorithm that works well for set intersection; by contrast, MPC for set intersection is a mature and practical technology that has seen real-world deployment.
Conclusion
In conclusion, both secure multiparty computation and differential privacy can be used to perform computations on sensitive data while preserving the privacy of those data. Important differences between the bodies of technique include
- The nature of the privacy guarantee: Use of MPC to compute a function y = f(x1, x2, ..., xn) guarantees that the recipients of the result learn the output y and nothing more. For example, if there are exactly two input vectors that are mapped to y by f, the recipients of the output y gain no information about which of two was the actual input to the MPC computation, regardless of the number of components in which these two input vectors differ or the magnitude of the differences. On the other hand, for any third input vector that does not map to y, the recipient learns with certainty that the real input to the MPC computation was not this third vector, even if it differs from one of the first two in only one component and only by a very small amount. By contrast, computing f with a DP algorithm guarantees that, for any two input vectors that differ in only one component, the (randomized!) results of the computation are approximately indistinguishable, regardless of whether the exact values of f on these two input vectors are equal, nearly equal, or extremely different. Straightforward use of composition yields a privacy guarantee for inputs that differ in c components at the expense of increasing the privacy parameter by a factor of c.
- Typical use cases: DP techniques are most often used to compute aggregate properties of very large datasets, and typically, the identities of data contributors are not known. None of these conditions is typical of MPC use cases.
- Exact vs. noisy answers: MPC can be used to compute exact answers for all functions f. DP requires the addition of noise. This is not a problem in many statistical computations, but even small amounts of noise may not be acceptable in some application scenarios. Moreover, if f is extremely sensitive to outliers in the input data, the amount of noise needed to achieve meaningful privacy may preclude meaningful accuracy.
- Auxiliary information: Combining the result of a DP computation with auxiliary information cannot result in privacy loss. By contrast, any computational method (including MPC) that returns the exact value y of a function f runs the risk that a recipient of y might be able to infer something about the input data that is not implied by y alone, if y is combined with auxiliary information.
Finally, we would like to point out that, in some applications, it is possible to get the benefits of both MPC and DP. If the goal is to compute f, and g is a differentially private approximation of f that achieves good privacy and accuracy simultaneously, then one natural way to proceed is to use MPC to compute g. We expect to see both MPC and DP used to enhance data privacy in Amazon’s products and services.
![At left is a neural network, labeled "pre-edit model", each of whose input nodes receives a single token from the string "<CLS> The high minded dismissal [SEP] A dismissal of a higher mind". The output of the model is the prediction "Contradict". Encodings from the network pass to a block labeled "SaLEM", in which gradients for each input token are calculated and the most-salient layer identified. The outputs of the block are edits to the layer weights. At right is another version of the neural network at left, labeled "post-edit model". Here, the output is "Entailed" rather than "Contradict".](https://assets.amazon.science/dims4/default/7114eff/2147483647/strip/true/crop/4000x2243+0+0/resize/535x300!/quality/90/?url=http%3A%2F%2Famazon-topics-brightspot.s3.amazonaws.com%2Fscience%2Ffc%2F84%2F2aa85e0645d9b139cedded97c66b%2Fsalem-architecture.png)

